BPF Architecture
BPF does not define itself by only providing its instruction set, but also by offering further infrastructure around it such as maps which act as efficient key / value stores, helper functions to interact with and leverage kernel functionality, tail calls for calling into other BPF programs, security hardening primitives, a pseudo file system for pinning objects (maps, programs), and infrastructure for allowing BPF to be offloaded, for example, to a network card.
LLVM provides a BPF back end, so that tools like clang can be used to compile C into a BPF object file, which can then be loaded into the kernel. BPF is deeply tied to the Linux kernel and allows for full programmability without sacrificing native kernel performance.
Last but not least, also the kernel subsystems making use of BPF are part of BPF’s infrastructure. The two main subsystems discussed throughout this document are tc and XDP where BPF programs can be attached to. XDP BPF programs are attached at the earliest networking driver stage and trigger a run of the BPF program upon packet reception. By definition, this achieves the best possible packet processing performance since packets cannot get processed at an even earlier point in software. However, since this processing occurs so early in the networking stack, the stack has not yet extracted metadata out of the packet. On the other hand, tc BPF programs are executed later in the kernel stack, so they have access to more metadata and core kernel functionality. Apart from tc and XDP programs, various other kernel subsystems use BPF, such as tracing (via kprobes, uprobes, tracepoints, for example).
The following subsections provide further details on individual aspects of the BPF architecture.
Instruction Set
BPF is a general purpose RISC instruction set and was originally designed for the purpose of writing programs in a subset of C which can be compiled into BPF instructions through a compiler back end (e.g. LLVM), so that the kernel can later on map them through an in-kernel JIT compiler into native opcodes for optimal execution performance inside the kernel.
The advantages for pushing these instructions into the kernel include:
Making the kernel programmable without having to cross kernel / user space boundaries. For example, BPF programs related to networking, as in the case of Cilium, can implement flexible container policies, load balancing and other means without having to move packets to user space and back into the kernel. State between BPF programs and kernel / user space can still be shared through maps whenever needed.
Given the flexibility of a programmable data path, programs can be heavily optimized for performance also by compiling out features that are not required for the use cases the program solves. For example, if a container does not require IPv4, then the BPF program can be built to only deal with IPv6 in order to save resources in the fast-path.
In case of networking (e.g. tc and XDP), BPF programs can be updated atomically without having to restart the kernel, system services or containers, and without traffic interruptions. Furthermore, any program state can also be maintained throughout updates via BPF maps.
BPF provides a stable ABI towards user space, and does not require any third party kernel modules. BPF is a core part of the Linux kernel that is shipped everywhere, and guarantees that existing BPF programs keep running with newer kernel versions. This guarantee is the same guarantee that the kernel provides for system calls with regard to user space applications. Moreover, BPF programs are portable across different architectures.
BPF programs work in concert with the kernel, they make use of existing kernel infrastructure (e.g. drivers, netdevices, tunnels, protocol stack, sockets) and tooling (e.g. iproute2) as well as the safety guarantees which the kernel provides. Unlike kernel modules, BPF programs are verified through an in-kernel verifier in order to ensure that they cannot crash the kernel, always terminate, etc. XDP programs, for example, reuse the existing in-kernel drivers and operate on the provided DMA buffers containing the packet frames without exposing them or an entire driver to user space as in other models. Moreover, XDP programs reuse the existing stack instead of bypassing it. BPF can be considered a generic “glue code” between kernel facilities for crafting programs to solve specific use cases.
The execution of a BPF program inside the kernel is always event-driven! Examples:
A networking device which has a BPF program attached on its ingress path will trigger the execution of the program once a packet is received.
A kernel address which has a kprobe with a BPF program attached will trap once the code at that address gets executed, which will then invoke the kprobe’s callback function for instrumentation, subsequently triggering the execution of the attached BPF program.
BPF consists of eleven 64 bit registers with 32 bit subregisters, a program counter
and a 512 byte large BPF stack space. Registers are named r0 - r10. The
operating mode is 64 bit by default, the 32 bit subregisters can only be accessed
through special ALU (arithmetic logic unit) operations. The 32 bit lower subregisters
zero-extend into 64 bit when they are being written to.
Register r10 is the only register which is read-only and contains the frame pointer
address in order to access the BPF stack space. The remaining r0 - r9
registers are general purpose and of read/write nature.
A BPF program can call into a predefined helper function, which is defined by the core kernel (never by modules). The BPF calling convention is defined as follows:
r0contains the return value of a helper function call.r1-r5hold arguments from the BPF program to the kernel helper function.r6-r9are callee saved registers that will be preserved on helper function call.
The BPF calling convention is generic enough to map directly to x86_64, arm64
and other ABIs, thus all BPF registers map one to one to HW CPU registers, so that a
JIT only needs to issue a call instruction, but no additional extra moves for placing
function arguments. This calling convention was modeled to cover common call
situations without having a performance penalty. Calls with 6 or more arguments
are currently not supported. The helper functions in the kernel which are dedicated
to BPF (BPF_CALL_0() to BPF_CALL_5() functions) are specifically designed
with this convention in mind.
Register r0 is also the register containing the exit value for the BPF program.
The semantics of the exit value are defined by the type of program. Furthermore, when
handing execution back to the kernel, the exit value is passed as a 32 bit value.
Registers r1 - r5 are scratch registers, meaning the BPF program needs to
either spill them to the BPF stack or move them to callee saved registers if these
arguments are to be reused across multiple helper function calls. Spilling means
that the variable in the register is moved to the BPF stack. The reverse operation
of moving the variable from the BPF stack to the register is called filling. The
reason for spilling/filling is due to the limited number of registers.
Upon entering execution of a BPF program, register r1 initially contains the
context for the program. The context is the input argument for the program (similar
to argc/argv pair for a typical C program). BPF is restricted to work on a single
context. The context is defined by the program type, for example, a networking
program can have a kernel representation of the network packet (skb) as the
input argument.
The general operation of BPF is 64 bit to follow the natural model of 64 bit architectures in order to perform pointer arithmetics, pass pointers but also pass 64 bit values into helper functions, and to allow for 64 bit atomic operations.
The maximum instruction limit per program is restricted to 4096 BPF instructions, which, by design, means that any program will terminate quickly. For kernel newer than 5.1 this limit was lifted to 1 million BPF instructions. Although the instruction set contains forward as well as backward jumps, the in-kernel BPF verifier will forbid loops so that termination is always guaranteed. Since BPF programs run inside the kernel, the verifier’s job is to make sure that these are safe to run, not affecting the system’s stability. This means that from an instruction set point of view, loops can be implemented, but the verifier will restrict that. However, there is also a concept of tail calls that allows for one BPF program to jump into another one. This, too, comes with an upper nesting limit of 33 calls, and is usually used to decouple parts of the program logic, for example, into stages.
The instruction format is modeled as two operand instructions, which helps mapping
BPF instructions to native instructions during JIT phase. The instruction set is
of fixed size, meaning every instruction has 64 bit encoding. Currently, 87 instructions
have been implemented and the encoding also allows to extend the set with further
instructions when needed. The instruction encoding of a single 64 bit instruction on a
big-endian machine is defined as a bit sequence from most significant bit (MSB) to least
significant bit (LSB) of op:8, dst_reg:4, src_reg:4, off:16, imm:32.
off and imm is of signed type. The encodings are part of the kernel headers and
defined in linux/bpf.h header, which also includes linux/bpf_common.h.
op defines the actual operation to be performed. Most of the encoding for op
has been reused from cBPF. The operation can be based on register or immediate
operands. The encoding of op itself provides information on which mode to use
(BPF_X for denoting register-based operations, and BPF_K for immediate-based
operations respectively). In the latter case, the destination operand is always
a register. Both dst_reg and src_reg provide additional information about
the register operands to be used (e.g. r0 - r9) for the operation. off
is used in some instructions to provide a relative offset, for example, for addressing
the stack or other buffers available to BPF (e.g. map values, packet data, etc),
or jump targets in jump instructions. imm contains a constant / immediate value.
The available op instructions can be categorized into various instruction
classes. These classes are also encoded inside the op field. The op field
is divided into (from MSB to LSB) code:4, source:1 and class:3. class
is the more generic instruction class, code denotes a specific operational
code inside that class, and source tells whether the source operand is a register
or an immediate value. Possible instruction classes include:
BPF_LD,BPF_LDX: Both classes are for load operations.BPF_LDis used for loading a double word as a special instruction spanning two instructions due to theimm:32split, and for byte / half-word / word loads of packet data. The latter was carried over from cBPF mainly in order to keep cBPF to BPF translations efficient, since they have optimized JIT code. For native BPF these packet load instructions are less relevant nowadays.BPF_LDXclass holds instructions for byte / half-word / word / double-word loads out of memory. Memory in this context is generic and could be stack memory, map value data, packet data, etc.BPF_ST,BPF_STX: Both classes are for store operations. Similar toBPF_LDXtheBPF_STXis the store counterpart and is used to store the data from a register into memory, which, again, can be stack memory, map value, packet data, etc.BPF_STXalso holds special instructions for performing word and double-word based atomic add operations, which can be used for counters, for example. TheBPF_STclass is similar toBPF_STXby providing instructions for storing data into memory only that the source operand is an immediate value.BPF_ALU,BPF_ALU64: Both classes contain ALU operations. Generally,BPF_ALUoperations are in 32 bit mode andBPF_ALU64in 64 bit mode. Both ALU classes have basic operations with source operand which is register-based and an immediate-based counterpart. Supported by both are add (+), sub (-), and (&), or (|), left shift (<<), right shift (>>), xor (^), mul (*), div (/), mod (%), neg (~) operations. Also mov (<X> := <Y>) was added as a special ALU operation for both classes in both operand modes.BPF_ALU64also contains a signed right shift.BPF_ALUadditionally contains endianness conversion instructions for half-word / word / double-word on a given source register.BPF_JMP: This class is dedicated to jump operations. Jumps can be unconditional and conditional. Unconditional jumps simply move the program counter forward, so that the next instruction to be executed relative to the current instruction isoff + 1, whereoffis the constant offset encoded in the instruction. Sinceoffis signed, the jump can also be performed backwards as long as it does not create a loop and is within program bounds. Conditional jumps operate on both, register-based and immediate-based source operands. If the condition in the jump operations results intrue, then a relative jump tooff + 1is performed, otherwise the next instruction (0 + 1) is performed. This fall-through jump logic differs compared to cBPF and allows for better branch prediction as it fits the CPU branch predictor logic more naturally. Available conditions are jeq (==), jne (!=), jgt (>), jge (>=), jsgt (signed>), jsge (signed>=), jlt (<), jle (<=), jslt (signed<), jsle (signed<=) and jset (jump ifDST & SRC). Apart from that, there are three special jump operations within this class: the exit instruction which will leave the BPF program and return the current value inr0as a return code, the call instruction, which will issue a function call into one of the available BPF helper functions, and a hidden tail call instruction, which will jump into a different BPF program.
The Linux kernel is shipped with a BPF interpreter which executes programs assembled in BPF instructions. Even cBPF programs are translated into eBPF programs transparently in the kernel, except for architectures that still ship with a cBPF JIT and have not yet migrated to an eBPF JIT.
Currently x86_64, arm64, ppc64, s390x, mips64, sparc64 and
arm architectures come with an in-kernel eBPF JIT compiler.
All BPF handling such as loading of programs into the kernel or creation of BPF maps
is managed through a central bpf() system call. It is also used for managing map
entries (lookup / update / delete), and making programs as well as maps persistent
in the BPF file system through pinning.
Helper Functions
Helper functions are a concept which enables BPF programs to consult a core kernel defined set of function calls in order to retrieve / push data from / to the kernel. Available helper functions may differ for each BPF program type, for example, BPF programs attached to sockets are only allowed to call into a subset of helpers compared to BPF programs attached to the tc layer. Encapsulation and decapsulation helpers for lightweight tunneling constitute an example of functions which are only available to lower tc layers, whereas event output helpers for pushing notifications to user space are available to tc and XDP programs.
Each helper function is implemented with a commonly shared function signature similar to system calls. The signature is defined as:
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)
The calling convention as described in the previous section applies to all BPF helper functions.
The kernel abstracts helper functions into macros BPF_CALL_0() to BPF_CALL_5()
which are similar to those of system calls. The following example is an extract
from a helper function which updates map elements by calling into the
corresponding map implementation callbacks:
BPF_CALL_4(bpf_map_update_elem, struct bpf_map *, map, void *, key,
void *, value, u64, flags)
{
WARN_ON_ONCE(!rcu_read_lock_held());
return map->ops->map_update_elem(map, key, value, flags);
}
const struct bpf_func_proto bpf_map_update_elem_proto = {
.func = bpf_map_update_elem,
.gpl_only = false,
.ret_type = RET_INTEGER,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_PTR_TO_MAP_KEY,
.arg3_type = ARG_PTR_TO_MAP_VALUE,
.arg4_type = ARG_ANYTHING,
};
There are various advantages of this approach: while cBPF overloaded its load instructions in order to fetch data at an impossible packet offset to invoke auxiliary helper functions, each cBPF JIT needed to implement support for such a cBPF extension. In case of eBPF, each newly added helper function will be JIT compiled in a transparent and efficient way, meaning that the JIT compiler only needs to emit a call instruction since the register mapping is made in such a way that BPF register assignments already match the underlying architecture’s calling convention. This allows for easily extending the core kernel with new helper functionality. All BPF helper functions are part of the core kernel and cannot be extended or added through kernel modules.
The aforementioned function signature also allows the verifier to perform type
checks. The above struct bpf_func_proto is used to hand all the necessary
information that needs to be known about the helper to the verifier, so that
the verifier can make sure that the expected types from the helper match the
current contents of the BPF program’s analyzed registers.
Argument types can range from passing in any kind of value up to restricted contents such as a pointer / size pair for the BPF stack buffer, which the helper should read from or write to. In the latter case, the verifier can also perform additional checks, for example, whether the buffer was previously initialized.
The list of available BPF helper functions is rather long and constantly growing,
for example, at the time of this writing, tc BPF programs can choose from 38
different BPF helpers. The kernel’s struct bpf_verifier_ops contains a
get_func_proto callback function that provides the mapping of a specific
enum bpf_func_id to one of the available helpers for a given BPF program
type.
Maps
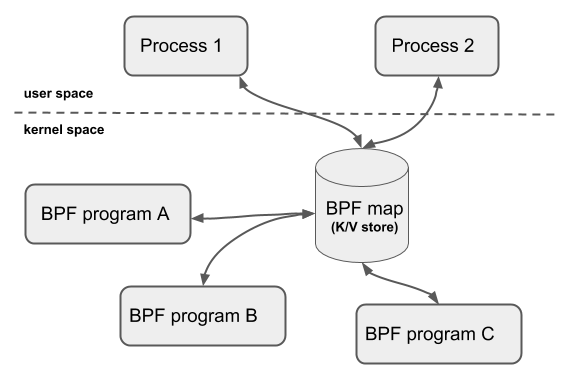
Maps are efficient key / value stores that reside in kernel space. They can be accessed from a BPF program in order to keep state among multiple BPF program invocations. They can also be accessed through file descriptors from user space and can be arbitrarily shared with other BPF programs or user space applications.
BPF programs which share maps with each other are not required to be of the same program type, for example, tracing programs can share maps with networking programs. A single BPF program can currently access up to 64 different maps directly.
Map implementations are provided by the core kernel. There are generic maps with per-CPU and non-per-CPU flavor that can read / write arbitrary data, but there are also a few non-generic maps that are used along with helper functions.
Generic maps currently available are BPF_MAP_TYPE_HASH, BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH, BPF_MAP_TYPE_PERCPU_ARRAY, BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH and BPF_MAP_TYPE_LPM_TRIE. They all use the
same common set of BPF helper functions in order to perform lookup, update or
delete operations while implementing a different backend with differing semantics
and performance characteristics.
Non-generic maps that are currently in the kernel are BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY, BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_STACK_TRACE, BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS. For example, BPF_MAP_TYPE_PROG_ARRAY is an
array map which holds other BPF programs, BPF_MAP_TYPE_ARRAY_OF_MAPS and
BPF_MAP_TYPE_HASH_OF_MAPS both hold pointers to other maps such that entire
BPF maps can be atomically replaced at runtime. These types of maps tackle a
specific issue which was unsuitable to be implemented solely through a BPF helper
function since additional (non-data) state is required to be held across BPF
program invocations.
Object Pinning
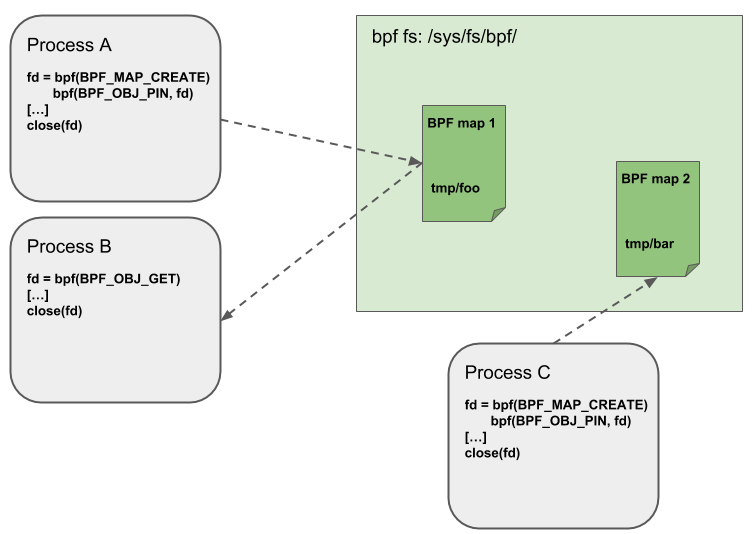
BPF maps and programs act as a kernel resource and can only be accessed through file descriptors, backed by anonymous inodes in the kernel. Advantages, but also a number of disadvantages come along with them:
User space applications can make use of most file descriptor related APIs, file descriptor passing for Unix domain sockets work transparently, etc, but at the same time, file descriptors are limited to a processes’ lifetime, which makes options like map sharing rather cumbersome to carry out.
Thus, it brings a number of complications for certain use cases such as iproute2, where tc or XDP sets up and loads the program into the kernel and terminates itself eventually. With that, also access to maps is unavailable from user space side, where it could otherwise be useful, for example, when maps are shared between ingress and egress locations of the data path. Also, third party applications may wish to monitor or update map contents during BPF program runtime.
To overcome this limitation, a minimal kernel space BPF file system has been
implemented, where BPF map and programs can be pinned to, a process called
object pinning. The BPF system call has therefore been extended with two new
commands which can pin (BPF_OBJ_PIN) or retrieve (BPF_OBJ_GET) a
previously pinned object.
For instance, tools such as tc make use of this infrastructure for sharing maps on ingress and egress. The BPF related file system is not a singleton, it does support multiple mount instances, hard and soft links, etc.
Tail Calls
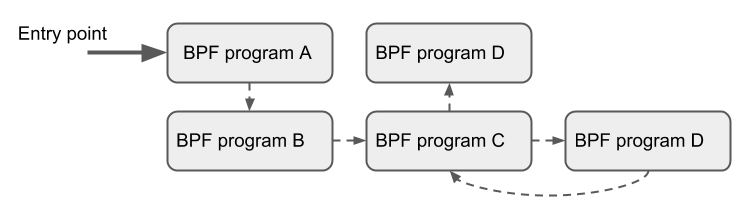
Another concept that can be used with BPF is called tail calls. Tail calls can be seen as a mechanism that allows one BPF program to call another, without returning back to the old program. Such a call has minimal overhead as unlike function calls, it is implemented as a long jump, reusing the same stack frame.
Such programs are verified independently of each other, thus for transferring
state, either per-CPU maps as scratch buffers or in case of tc programs, skb
fields such as the cb[] area must be used.
Only programs of the same type can be tail called, and they also need to match in terms of JIT compilation, thus either JIT compiled or only interpreted programs can be invoked, but not mixed together.
There are two components involved for carrying out tail calls: the first part
needs to setup a specialized map called program array (BPF_MAP_TYPE_PROG_ARRAY)
that can be populated by user space with key / values, where values are the
file descriptors of the tail called BPF programs, the second part is a
bpf_tail_call() helper where the context, a reference to the program array
and the lookup key is passed to. Then the kernel inlines this helper call
directly into a specialized BPF instruction. Such a program array is currently
write-only from user space side.
The kernel looks up the related BPF program from the passed file descriptor
and atomically replaces program pointers at the given map slot. When no map
entry has been found at the provided key, the kernel will just “fall through”
and continue execution of the old program with the instructions following
after the bpf_tail_call(). Tail calls are a powerful utility, for example,
parsing network headers could be structured through tail calls. During runtime,
functionality can be added or replaced atomically, and thus altering the BPF
program’s execution behavior.
BPF to BPF Calls
Aside from BPF helper calls and BPF tail calls, a more recent feature that has
been added to the BPF core infrastructure is BPF to BPF calls. Before this
feature was introduced into the kernel, a typical BPF C program had to declare
any reusable code that, for example, resides in headers as always_inline
such that when LLVM compiles and generates the BPF object file all these
functions were inlined and therefore duplicated many times in the resulting
object file, artificially inflating its code size:
#include <linux/bpf.h>
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
#ifndef __inline
# define __inline \
inline __attribute__((always_inline))
#endif
static __inline int foo(void)
{
return XDP_DROP;
}
__section("prog")
int xdp_drop(struct xdp_md *ctx)
{
return foo();
}
char __license[] __section("license") = "GPL";
The main reason why this was necessary was due to lack of function call support
in the BPF program loader as well as verifier, interpreter and JITs. Starting
with Linux kernel 4.16 and LLVM 6.0 this restriction got lifted and BPF programs
no longer need to use always_inline everywhere. Thus, the prior shown BPF
example code can then be rewritten more naturally as:
#include <linux/bpf.h>
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
static int foo(void)
{
return XDP_DROP;
}
__section("prog")
int xdp_drop(struct xdp_md *ctx)
{
return foo();
}
char __license[] __section("license") = "GPL";
Mainstream BPF JIT compilers like x86_64 and arm64 support BPF to BPF
calls today with others following in near future. BPF to BPF call is an
important performance optimization since it heavily reduces the generated BPF
code size and therefore becomes friendlier to a CPU’s instruction cache.
The calling convention known from BPF helper function applies to BPF to BPF
calls just as well, meaning r1 up to r5 are for passing arguments to
the callee and the result is returned in r0. r1 to r5 are scratch
registers whereas r6 to r9 preserved across calls the usual way. The
maximum number of nesting calls respectively allowed call frames is 8.
A caller can pass pointers (e.g. to the caller’s stack frame) down to the
callee, but never vice versa.
BPF JIT compilers emit separate images for each function body and later fix up the function call addresses in the image in a final JIT pass. This has proven to require minimal changes to the JITs in that they can treat BPF to BPF calls as conventional BPF helper calls.
Up to kernel 5.9, BPF tail calls and BPF subprograms excluded each other. BPF programs that utilized tail calls couldn’t take the benefit of reducing program image size and faster load times. Linux kernel 5.10 finally allows users to bring the best of two worlds and adds the ability to combine the BPF subprograms with tail calls.
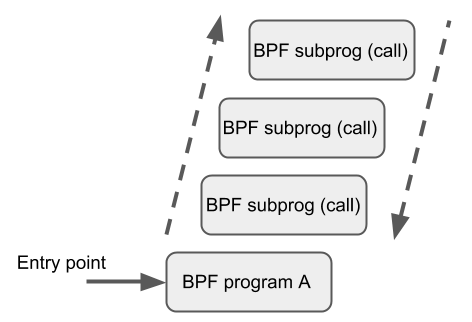
This improvement comes with some restrictions, though. Mixing these two features can cause a kernel stack overflow. To get an idea of what might happen, see the picture below that illustrates the mix of bpf2bpf calls and tail calls:
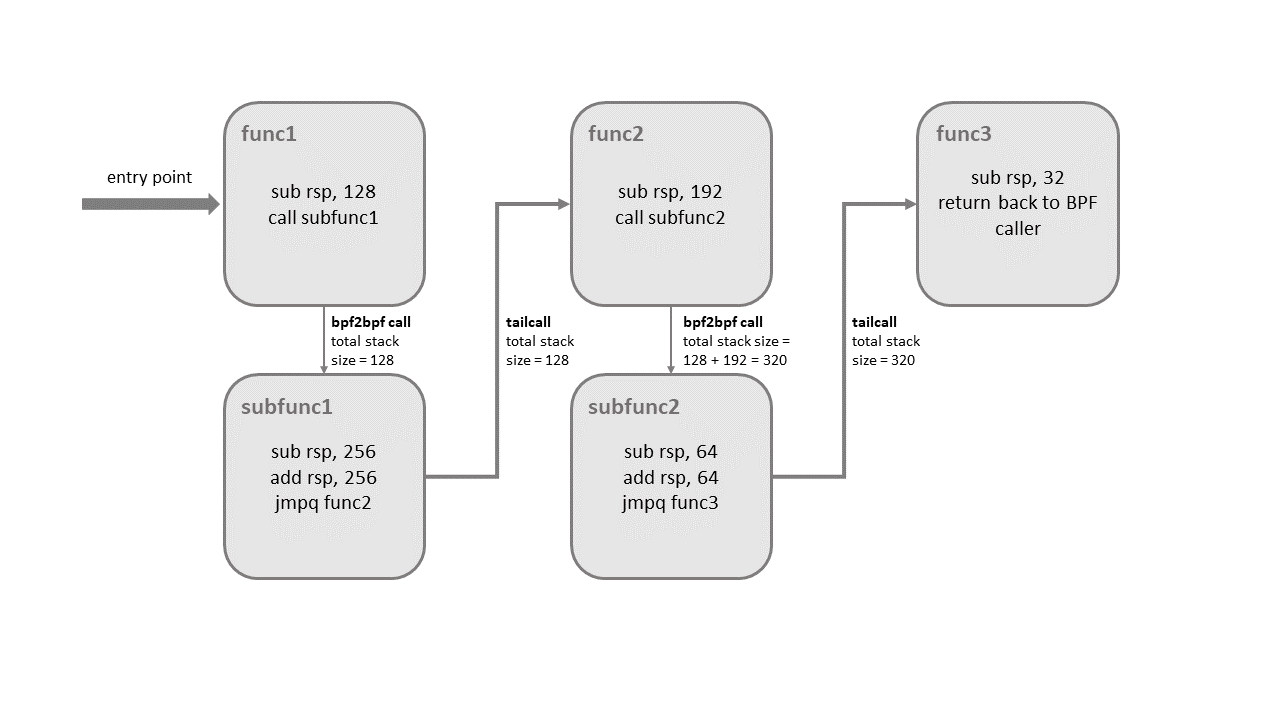
Tail calls, before the actual jump to the target program, will unwind only its current stack frame. As we can see in the example above, if a tail call occurs from within the sub-function, the function’s (func1) stack frame will be present on the stack when a program execution is at func2. Once the final function (func3) function terminates, all the previous stack frames will be unwinded and control will get back to the caller of BPF program caller.
The kernel introduced additional logic for detecting this feature combination. There is a limit on the stack size throughout the whole call chain down to 256 bytes per subprogram (note that if the verifier detects the bpf2bpf call, then the main function is treated as a sub-function as well). In total, with this restriction, the BPF program’s call chain can consume at most 8KB of stack space. This limit comes from the 256 bytes per stack frame multiplied by the tail call count limit (33). Without this, the BPF programs will operate on 512-byte stack size, yielding the 16KB size in total for the maximum count of tail calls that would overflow the stack on some architectures.
One more thing to mention is that this feature combination is currently supported only on the x86-64 architecture.
JIT
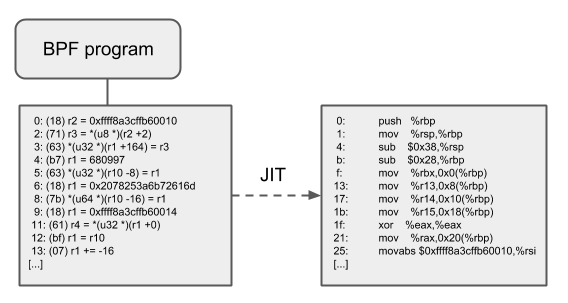
The 64 bit x86_64, arm64, ppc64, s390x, mips64, sparc64
and 32 bit arm, x86_32 architectures are all shipped with an in-kernel
eBPF JIT compiler, also all of them are feature equivalent and can be enabled
through:
# echo 1 > /proc/sys/net/core/bpf_jit_enable
The 32 bit mips, ppc and sparc architectures currently have a cBPF
JIT compiler. The mentioned architectures still having a cBPF JIT as well as all
remaining architectures supported by the Linux kernel which do not have a BPF JIT
compiler at all need to run eBPF programs through the in-kernel interpreter.
In the kernel’s source tree, eBPF JIT support can be easily determined through
issuing a grep for HAVE_EBPF_JIT:
# git grep HAVE_EBPF_JIT arch/
arch/arm/Kconfig: select HAVE_EBPF_JIT if !CPU_ENDIAN_BE32
arch/arm64/Kconfig: select HAVE_EBPF_JIT
arch/powerpc/Kconfig: select HAVE_EBPF_JIT if PPC64
arch/mips/Kconfig: select HAVE_EBPF_JIT if (64BIT && !CPU_MICROMIPS)
arch/s390/Kconfig: select HAVE_EBPF_JIT if PACK_STACK && HAVE_MARCH_Z196_FEATURES
arch/sparc/Kconfig: select HAVE_EBPF_JIT if SPARC64
arch/x86/Kconfig: select HAVE_EBPF_JIT if X86_64
JIT compilers speed up execution of the BPF program significantly since they
reduce the per instruction cost compared to the interpreter. Often instructions
can be mapped 1:1 with native instructions of the underlying architecture. This
also reduces the resulting executable image size and is therefore more
instruction cache friendly to the CPU. In particular in case of CISC instruction
sets such as x86, the JITs are optimized for emitting the shortest possible
opcodes for a given instruction to shrink the total necessary size for the
program translation.
Hardening
BPF locks the entire BPF interpreter image (struct bpf_prog) as well
as the JIT compiled image (struct bpf_binary_header) in the kernel as
read-only during the program’s lifetime in order to prevent the code from
potential corruptions. Any corruption happening at that point, for example,
due to some kernel bugs will result in a general protection fault and thus
crash the kernel instead of allowing the corruption to happen silently.
Architectures that support setting the image memory as read-only can be determined through:
$ git grep ARCH_HAS_SET_MEMORY | grep select
arch/arm/Kconfig: select ARCH_HAS_SET_MEMORY
arch/arm64/Kconfig: select ARCH_HAS_SET_MEMORY
arch/s390/Kconfig: select ARCH_HAS_SET_MEMORY
arch/x86/Kconfig: select ARCH_HAS_SET_MEMORY
The option CONFIG_ARCH_HAS_SET_MEMORY is not configurable, thanks to
which this protection is always built in. Other architectures might follow
in the future.
In case of the x86_64 JIT compiler, the JITing of the indirect jump from
the use of tail calls is realized through a retpoline in case CONFIG_RETPOLINE
has been set which is the default at the time of writing in most modern Linux
distributions.
In case of /proc/sys/net/core/bpf_jit_harden set to 1 additional
hardening steps for the JIT compilation take effect for unprivileged users.
This effectively trades off their performance slightly by decreasing a
(potential) attack surface in case of untrusted users operating on the
system. The decrease in program execution still results in better performance
compared to switching to interpreter entirely.
Currently, enabling hardening will blind all user provided 32 bit and 64 bit constants from the BPF program when it gets JIT compiled in order to prevent JIT spraying attacks which inject native opcodes as immediate values. This is problematic as these immediate values reside in executable kernel memory, therefore, a jump that could be triggered from some kernel bug would jump to the start of the immediate value and then execute these as native instructions.
JIT constant blinding prevents this due to randomizing the actual instruction,
which means the operation is transformed from an immediate based source operand
to a register based one through rewriting the instruction by splitting the
actual load of the value into two steps: 1) load of a blinded immediate
value rnd ^ imm into a register, 2) xoring that register with rnd
such that the original imm immediate then resides in the register and
can be used for the actual operation. The example was provided for a load
operation, but really all generic operations are blinded.
Example of JITing a program with hardening disabled:
# echo 0 > /proc/sys/net/core/bpf_jit_harden
ffffffffa034f5e9 + <x>:
[...]
39: mov $0xa8909090,%eax
3e: mov $0xa8909090,%eax
43: mov $0xa8ff3148,%eax
48: mov $0xa89081b4,%eax
4d: mov $0xa8900bb0,%eax
52: mov $0xa810e0c1,%eax
57: mov $0xa8908eb4,%eax
5c: mov $0xa89020b0,%eax
[...]
The same program gets constant blinded when loaded through BPF as an unprivileged user in the case hardening is enabled:
# echo 1 > /proc/sys/net/core/bpf_jit_harden
ffffffffa034f1e5 + <x>:
[...]
39: mov $0xe1192563,%r10d
3f: xor $0x4989b5f3,%r10d
46: mov %r10d,%eax
49: mov $0xb8296d93,%r10d
4f: xor $0x10b9fd03,%r10d
56: mov %r10d,%eax
59: mov $0x8c381146,%r10d
5f: xor $0x24c7200e,%r10d
66: mov %r10d,%eax
69: mov $0xeb2a830e,%r10d
6f: xor $0x43ba02ba,%r10d
76: mov %r10d,%eax
79: mov $0xd9730af,%r10d
7f: xor $0xa5073b1f,%r10d
86: mov %r10d,%eax
89: mov $0x9a45662b,%r10d
8f: xor $0x325586ea,%r10d
96: mov %r10d,%eax
[...]
Both programs are semantically the same, only that none of the original immediate values are visible anymore in the disassembly of the second program.
At the same time, hardening also disables any JIT kallsyms exposure
for privileged users, preventing that JIT image addresses are not
exposed to /proc/kallsyms anymore.
Moreover, the Linux kernel provides the option CONFIG_BPF_JIT_ALWAYS_ON
which removes the entire BPF interpreter from the kernel and permanently
enables the JIT compiler. This has been developed as part of a mitigation
in the context of Spectre v2 such that when used in a VM-based setting,
the guest kernel is not going to reuse the host kernel’s BPF interpreter
when mounting an attack anymore. For container-based environments, the
CONFIG_BPF_JIT_ALWAYS_ON configuration option is optional, but in
case JITs are enabled there anyway, the interpreter may as well be compiled
out to reduce the kernel’s complexity. Thus, it is also generally
recommended for widely used JITs in case of mainstream architectures
such as x86_64 and arm64.
Last but not least, the kernel offers an option to disable the use of
the bpf(2) system call for unprivileged users through the
/proc/sys/kernel/unprivileged_bpf_disabled sysctl knob. This is
on purpose a one-time kill switch, meaning once set to 1, there is
no option to reset it back to 0 until a new kernel reboot. When
set only CAP_SYS_ADMIN privileged processes out of the initial
namespace are allowed to use the bpf(2) system call from that
point onwards. Upon start, Cilium sets this knob to 1 as well.
# echo 1 > /proc/sys/kernel/unprivileged_bpf_disabled
Offloads
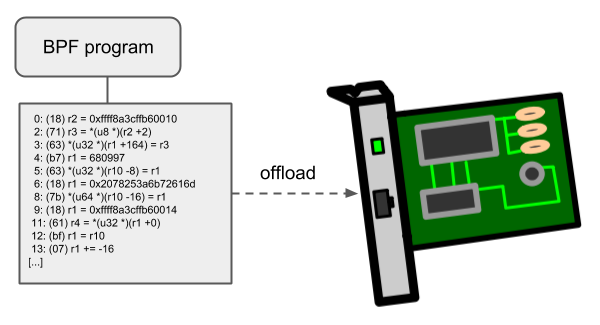
Networking programs in BPF, in particular for tc and XDP do have an offload-interface to hardware in the kernel in order to execute BPF code directly on the NIC.
Currently, the nfp driver from Netronome has support for offloading
BPF through a JIT compiler which translates BPF instructions to an
instruction set implemented against the NIC. This includes offloading
of BPF maps to the NIC as well, thus the offloaded BPF program can
perform map lookups, updates and deletions.
BPF sysctls
The Linux kernel provides few sysctls that are BPF related and covered in this section.
/proc/sys/net/core/bpf_jit_enable: Enables or disables the BPF JIT compiler.Value
Description
0
Disable the JIT and use only interpreter (kernel’s default value)
1
Enable the JIT compiler
2
Enable the JIT and emit debugging traces to the kernel log
As described in subsequent sections,
bpf_jit_disasmtool can be used to process debugging traces when the JIT compiler is set to debugging mode (option2)./proc/sys/net/core/bpf_jit_harden: Enables or disables BPF JIT hardening. Note that enabling hardening trades off performance, but can mitigate JIT spraying by blinding out the BPF program’s immediate values. For programs processed through the interpreter, blinding of immediate values is not needed / performed.Value
Description
0
Disable JIT hardening (kernel’s default value)
1
Enable JIT hardening for unprivileged users only
2
Enable JIT hardening for all users
/proc/sys/net/core/bpf_jit_kallsyms: Enables or disables export of JITed programs as kernel symbols to/proc/kallsymsso that they can be used together withperftooling as well as making these addresses aware to the kernel for stack unwinding, for example, used in dumping stack traces. The symbol names contain the BPF program tag (bpf_prog_<tag>). Ifbpf_jit_hardenis enabled, then this feature is disabled.Value
Description
0
Disable JIT kallsyms export (kernel’s default value)
1
Enable JIT kallsyms export for privileged users only
/proc/sys/kernel/unprivileged_bpf_disabled: Enables or disable unprivileged use of thebpf(2)system call. The Linux kernel has unprivileged use ofbpf(2)enabled by default.Once the value is set to 1, unprivileged use will be permanently disabled until the next reboot, neither an application nor an admin can reset the value anymore.
The value can also be set to 2, which means it can be changed at runtime to 0 or 1 later while disabling the unprivileged used for now. This value was added in Linux 5.13. If
BPF_UNPRIV_DEFAULT_OFFis enabled in the kernel config, then this knob will default to 2 instead of 0.This knob does not affect any cBPF programs such as seccomp or traditional socket filters that do not use the
bpf(2)system call for loading the program into the kernel.Value
Description
0
Unprivileged use of bpf syscall enabled (kernel’s default value)
1
Unprivileged use of bpf syscall disabled (until reboot)
2
Unprivileged use of bpf syscall disabled (default if
BPF_UNPRIV_DEFAULT_OFFis enabled in kernel config)