Debugging and Testing
bpftool
bpftool is the main introspection and debugging tool around BPF and developed
and shipped along with the Linux kernel tree under tools/bpf/bpftool/.
The tool can dump all BPF programs and maps that are currently loaded in the system, or list and correlate all BPF maps used by a specific program. Furthermore, it allows to dump the entire map’s key / value pairs, or lookup, update, delete individual ones as well as retrieve a key’s neighbor key in the map. Such operations can be performed based on BPF program or map IDs or by specifying the location of a BPF file system pinned program or map. The tool additionally also offers an option to pin maps or programs into the BPF file system.
For a quick overview of all BPF programs currently loaded on the host invoke the following command:
# bpftool prog
398: sched_cls tag 56207908be8ad877
loaded_at Apr 09/16:24 uid 0
xlated 8800B jited 6184B memlock 12288B map_ids 18,5,17,14
399: sched_cls tag abc95fb4835a6ec9
loaded_at Apr 09/16:24 uid 0
xlated 344B jited 223B memlock 4096B map_ids 18
400: sched_cls tag afd2e542b30ff3ec
loaded_at Apr 09/16:24 uid 0
xlated 1720B jited 1001B memlock 4096B map_ids 17
401: sched_cls tag 2dbbd74ee5d51cc8
loaded_at Apr 09/16:24 uid 0
xlated 3728B jited 2099B memlock 4096B map_ids 17
[...]
Similarly, to get an overview of all active maps:
# bpftool map
5: hash flags 0x0
key 20B value 112B max_entries 65535 memlock 13111296B
6: hash flags 0x0
key 20B value 20B max_entries 65536 memlock 7344128B
7: hash flags 0x0
key 10B value 16B max_entries 8192 memlock 790528B
8: hash flags 0x0
key 22B value 28B max_entries 8192 memlock 987136B
9: hash flags 0x0
key 20B value 8B max_entries 512000 memlock 49352704B
[...]
Note that for each command, bpftool also supports json based output by
appending --json at the end of the command line. An additional
--pretty improves the output to be more human readable.
# bpftool prog --json --pretty
For dumping the post-verifier BPF instruction image of a specific BPF program, one starting point could be to inspect a specific program, e.g. attached to the tc ingress hook:
# tc filter show dev cilium_host egress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 bpf_host.o:[from-netdev] \
direct-action not_in_hw id 406 tag e0362f5bd9163a0a jited
The program from the object file bpf_host.o, section from-netdev has
a BPF program ID of 406 as denoted in id 406. Based on this information
bpftool can provide some high-level metadata specific to the program:
# bpftool prog show id 406
406: sched_cls tag e0362f5bd9163a0a
loaded_at Apr 09/16:24 uid 0
xlated 11144B jited 7721B memlock 12288B map_ids 18,20,8,5,6,14
The program of ID 406 is of type sched_cls (BPF_PROG_TYPE_SCHED_CLS),
has a tag of e0362f5bd9163a0a (SHA sum over the instruction sequence),
it was loaded by root uid 0 on Apr 09/16:24. The BPF instruction
sequence is 11,144 bytes long and the JITed image 7,721 bytes. The
program itself (excluding maps) consumes 12,288 bytes that are accounted /
charged against user uid 0. And the BPF program uses the BPF maps with
IDs 18, 20, 8, 5, 6 and 14. The latter IDs can further
be used to get information or dump the map themselves.
Additionally, bpftool can issue a dump request of the BPF instructions the program runs:
# bpftool prog dump xlated id 406
0: (b7) r7 = 0
1: (63) *(u32 *)(r1 +60) = r7
2: (63) *(u32 *)(r1 +56) = r7
3: (63) *(u32 *)(r1 +52) = r7
[...]
47: (bf) r4 = r10
48: (07) r4 += -40
49: (79) r6 = *(u64 *)(r10 -104)
50: (bf) r1 = r6
51: (18) r2 = map[id:18] <-- BPF map id 18
53: (b7) r5 = 32
54: (85) call bpf_skb_event_output#5656112 <-- BPF helper call
55: (69) r1 = *(u16 *)(r6 +192)
[...]
bpftool correlates BPF map IDs into the instruction stream as shown above as well as calls to BPF helpers or other BPF programs.
The instruction dump reuses the same ‘pretty-printer’ as the kernel’s BPF
verifier. Since the program was JITed and therefore the actual JIT image
that was generated out of above xlated instructions is executed, it
can be dumped as well through bpftool:
# bpftool prog dump jited id 406
0: push %rbp
1: mov %rsp,%rbp
4: sub $0x228,%rsp
b: sub $0x28,%rbp
f: mov %rbx,0x0(%rbp)
13: mov %r13,0x8(%rbp)
17: mov %r14,0x10(%rbp)
1b: mov %r15,0x18(%rbp)
1f: xor %eax,%eax
21: mov %rax,0x20(%rbp)
25: mov 0x80(%rdi),%r9d
[...]
Mainly for BPF JIT developers, the option also exists to interleave the disassembly with the actual native opcodes:
# bpftool prog dump jited id 406 opcodes
0: push %rbp
55
1: mov %rsp,%rbp
48 89 e5
4: sub $0x228,%rsp
48 81 ec 28 02 00 00
b: sub $0x28,%rbp
48 83 ed 28
f: mov %rbx,0x0(%rbp)
48 89 5d 00
13: mov %r13,0x8(%rbp)
4c 89 6d 08
17: mov %r14,0x10(%rbp)
4c 89 75 10
1b: mov %r15,0x18(%rbp)
4c 89 7d 18
[...]
The same interleaving can be done for the normal BPF instructions which can sometimes be useful for debugging in the kernel:
# bpftool prog dump xlated id 406 opcodes
0: (b7) r7 = 0
b7 07 00 00 00 00 00 00
1: (63) *(u32 *)(r1 +60) = r7
63 71 3c 00 00 00 00 00
2: (63) *(u32 *)(r1 +56) = r7
63 71 38 00 00 00 00 00
3: (63) *(u32 *)(r1 +52) = r7
63 71 34 00 00 00 00 00
4: (63) *(u32 *)(r1 +48) = r7
63 71 30 00 00 00 00 00
5: (63) *(u32 *)(r1 +64) = r7
63 71 40 00 00 00 00 00
[...]
The basic blocks of a program can also be visualized with the help of
graphviz. For this purpose, bpftool has a visual dump mode that
generates a dot file instead of the plain BPF xlated instruction
dump that can later be converted to a png file:
# bpftool prog dump xlated id 406 visual &> output.dot
$ dot -Tpng output.dot -o output.png
Another option would be to pass the dot file to dotty as a viewer, that
is dotty output.dot, where the result for the bpf_host.o program
looks as follows (small extract):
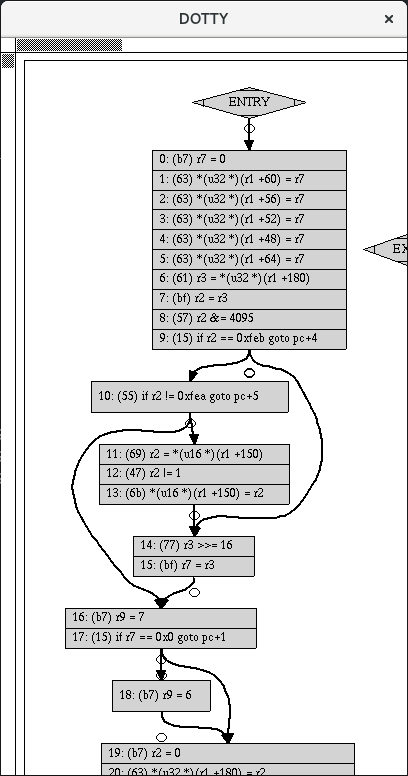
Note that the xlated instruction dump provides the post-verifier BPF
instruction image which means that it dumps the instructions as if they
were to be run through the BPF interpreter. In the kernel, the verifier
performs various rewrites of the original instructions provided by the
BPF loader.
One example of rewrites is the inlining of helper functions in order to improve runtime performance, here in the case of a map lookup for hash tables:
# bpftool prog dump xlated id 3
0: (b7) r1 = 2
1: (63) *(u32 *)(r10 -4) = r1
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = map[id:2] <-- BPF map id 2
6: (85) call __htab_map_lookup_elem#77408 <-+ BPF helper inlined rewrite
7: (15) if r0 == 0x0 goto pc+2 |
8: (07) r0 += 56 |
9: (79) r0 = *(u64 *)(r0 +0) <-+
10: (15) if r0 == 0x0 goto pc+24
11: (bf) r2 = r10
12: (07) r2 += -4
[...]
bpftool correlates calls to helper functions or BPF to BPF calls through
kallsyms. Therefore, make sure that JITed BPF programs are exposed to
kallsyms (bpf_jit_kallsyms) and that kallsyms addresses are not
obfuscated (calls are otherwise shown as call bpf_unspec#0):
# echo 0 > /proc/sys/kernel/kptr_restrict
# echo 1 > /proc/sys/net/core/bpf_jit_kallsyms
BPF to BPF calls are correlated as well for both, interpreter as well
as JIT case. In the latter, the tag of the subprogram is shown as
call target. In each case, the pc+2 is the pc-relative offset of
the call target, which denotes the subprogram.
# bpftool prog dump xlated id 1
0: (85) call pc+2#__bpf_prog_run_args32
1: (b7) r0 = 1
2: (95) exit
3: (b7) r0 = 2
4: (95) exit
JITed variant of the dump:
# bpftool prog dump xlated id 1
0: (85) call pc+2#bpf_prog_3b185187f1855c4c_F
1: (b7) r0 = 1
2: (95) exit
3: (b7) r0 = 2
4: (95) exit
In the case of tail calls, the kernel maps them into a single instruction internally, bpftool will still correlate them as a helper call for ease of debugging:
# bpftool prog dump xlated id 2
[...]
10: (b7) r2 = 8
11: (85) call bpf_trace_printk#-41312
12: (bf) r1 = r6
13: (18) r2 = map[id:1]
15: (b7) r3 = 0
16: (85) call bpf_tail_call#12
17: (b7) r1 = 42
18: (6b) *(u16 *)(r6 +46) = r1
19: (b7) r0 = 0
20: (95) exit
# bpftool map show id 1
1: prog_array flags 0x0
key 4B value 4B max_entries 1 memlock 4096B
Dumping an entire map is possible through the map dump subcommand
which iterates through all present map elements and dumps the key /
value pairs.
If no BTF (BPF Type Format) data is available for a given map, then the key / value pairs are dumped as hex:
# bpftool map dump id 5
key:
f0 0d 00 00 00 00 00 00 0a 66 00 00 00 00 8a d6
02 00 00 00
value:
00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
key:
0a 66 1c ee 00 00 00 00 00 00 00 00 00 00 00 00
01 00 00 00
value:
00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[...]
Found 6 elements
However, with BTF, the map also holds debugging information about
the key and value structures. For example, BTF in combination with
BPF maps and the BPF_ANNOTATE_KV_PAIR() macro from iproute2 will
result in the following dump (test_xdp_noinline.o from kernel
selftests):
# cat tools/testing/selftests/bpf/test_xdp_noinline.c
[...]
struct ctl_value {
union {
__u64 value;
__u32 ifindex;
__u8 mac[6];
};
};
struct bpf_map_def __attribute__ ((section("maps"), used)) ctl_array = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(__u32),
.value_size = sizeof(struct ctl_value),
.max_entries = 16,
.map_flags = 0,
};
BPF_ANNOTATE_KV_PAIR(ctl_array, __u32, struct ctl_value);
[...]
The BPF_ANNOTATE_KV_PAIR() macro forces a map-specific ELF section containing an empty key and value, this enables the iproute2 BPF loader to correlate BTF data with that section and thus allows to choose the corresponding types out of the BTF for loading the map.
Compiling through LLVM and generating BTF through debugging information
by pahole:
# clang [...] -O2 --target=bpf -g -emit-llvm -c test_xdp_noinline.c -o - |
llc -march=bpf -mcpu=probe -mattr=dwarfris -filetype=obj -o test_xdp_noinline.o
# pahole -J test_xdp_noinline.o
Now loading into kernel and dumping the map via bpftool:
# ip -force link set dev lo xdp obj test_xdp_noinline.o sec xdp-test
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric/id:227 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
[...]
# bpftool prog show id 227
227: xdp tag a85e060c275c5616 gpl
loaded_at 2018-07-17T14:41:29+0000 uid 0
xlated 8152B not jited memlock 12288B map_ids 381,385,386,382,384,383
# bpftool map dump id 386
[{
"key": 0,
"value": {
"": {
"value": 0,
"ifindex": 0,
"mac": []
}
}
},{
"key": 1,
"value": {
"": {
"value": 0,
"ifindex": 0,
"mac": []
}
}
},{
[...]
Lookup, update, delete, and ‘get next key’ operations on the map for specific keys can be performed through bpftool as well.
If the BPF program has been successfully loaded with BTF debugging information,
the BTF ID will be shown in prog show command result denoted in btf_id.
# bpftool prog show id 72
72: xdp name balancer_ingres tag acf44cabb48385ed gpl
loaded_at 2020-04-13T23:12:08+0900 uid 0
xlated 19104B jited 10732B memlock 20480B map_ids 126,130,131,127,129,128
btf_id 60
This can also be confirmed with btf show command which dumps all BTF
objects loaded on a system.
# bpftool btf show
60: size 12243B prog_ids 72 map_ids 126,130,131,127,129,128
And the subcommand btf dump can be used to check which debugging information
is included in the BTF. With this command, BTF dump can be formatted either
‘raw’ or ‘c’, the one that is used in C code.
# bpftool btf dump id 60 format c
[...]
struct ctl_value {
union {
__u64 value;
__u32 ifindex;
__u8 mac[6];
};
};
typedef unsigned int u32;
[...]
Video
To learn more about bpftool, check out eCHO episode 11: Exploring bpftool with Quentin Monnet, maintainer of bpftool.
Kernel Testing
The Linux kernel ships a BPF selftest suite, which can be found in the kernel
source tree under tools/testing/selftests/bpf/.
$ cd tools/testing/selftests/bpf/
$ make
# make run_tests
The test suite contains test cases against the BPF verifier, program tags, various tests against the BPF map interface and map types. It contains various runtime tests from C code for checking LLVM back end, and eBPF as well as cBPF asm code that is run in the kernel for testing the interpreter and JITs.
JIT Debugging
For JIT developers performing audits or writing extensions, each compile run can output the generated JIT image into the kernel log through:
# echo 2 > /proc/sys/net/core/bpf_jit_enable
Whenever a new BPF program is loaded, the JIT compiler will dump the output,
which can then be inspected with dmesg, for example:
[ 3389.935842] flen=6 proglen=70 pass=3 image=ffffffffa0069c8f from=tcpdump pid=20583
[ 3389.935847] JIT code: 00000000: 55 48 89 e5 48 83 ec 60 48 89 5d f8 44 8b 4f 68
[ 3389.935849] JIT code: 00000010: 44 2b 4f 6c 4c 8b 87 d8 00 00 00 be 0c 00 00 00
[ 3389.935850] JIT code: 00000020: e8 1d 94 ff e0 3d 00 08 00 00 75 16 be 17 00 00
[ 3389.935851] JIT code: 00000030: 00 e8 28 94 ff e0 83 f8 01 75 07 b8 ff ff 00 00
[ 3389.935852] JIT code: 00000040: eb 02 31 c0 c9 c3
flen is the length of the BPF program (here, 6 BPF instructions), and proglen
tells the number of bytes generated by the JIT for the opcode image (here, 70 bytes
in size). pass means that the image was generated in 3 compiler passes, for
example, x86_64 can have various optimization passes to further reduce the image
size when possible. image contains the address of the generated JIT image, from
and pid the user space application name and PID respectively, which triggered the
compilation process. The dump output for eBPF and cBPF JITs is the same format.
In the kernel tree under tools/bpf/, there is a tool called bpf_jit_disasm. It
reads out the latest dump and prints the disassembly for further inspection:
# ./bpf_jit_disasm
70 bytes emitted from JIT compiler (pass:3, flen:6)
ffffffffa0069c8f + <x>:
0: push %rbp
1: mov %rsp,%rbp
4: sub $0x60,%rsp
8: mov %rbx,-0x8(%rbp)
c: mov 0x68(%rdi),%r9d
10: sub 0x6c(%rdi),%r9d
14: mov 0xd8(%rdi),%r8
1b: mov $0xc,%esi
20: callq 0xffffffffe0ff9442
25: cmp $0x800,%eax
2a: jne 0x0000000000000042
2c: mov $0x17,%esi
31: callq 0xffffffffe0ff945e
36: cmp $0x1,%eax
39: jne 0x0000000000000042
3b: mov $0xffff,%eax
40: jmp 0x0000000000000044
42: xor %eax,%eax
44: leaveq
45: retq
Alternatively, the tool can also dump related opcodes along with the disassembly.
# ./bpf_jit_disasm -o
70 bytes emitted from JIT compiler (pass:3, flen:6)
ffffffffa0069c8f + <x>:
0: push %rbp
55
1: mov %rsp,%rbp
48 89 e5
4: sub $0x60,%rsp
48 83 ec 60
8: mov %rbx,-0x8(%rbp)
48 89 5d f8
c: mov 0x68(%rdi),%r9d
44 8b 4f 68
10: sub 0x6c(%rdi),%r9d
44 2b 4f 6c
14: mov 0xd8(%rdi),%r8
4c 8b 87 d8 00 00 00
1b: mov $0xc,%esi
be 0c 00 00 00
20: callq 0xffffffffe0ff9442
e8 1d 94 ff e0
25: cmp $0x800,%eax
3d 00 08 00 00
2a: jne 0x0000000000000042
75 16
2c: mov $0x17,%esi
be 17 00 00 00
31: callq 0xffffffffe0ff945e
e8 28 94 ff e0
36: cmp $0x1,%eax
83 f8 01
39: jne 0x0000000000000042
75 07
3b: mov $0xffff,%eax
b8 ff ff 00 00
40: jmp 0x0000000000000044
eb 02
42: xor %eax,%eax
31 c0
44: leaveq
c9
45: retq
c3
More recently, bpftool adapted the same feature of dumping the BPF JIT
image based on a given BPF program ID already loaded in the system (see
bpftool section).
For performance analysis of JITed BPF programs, perf can be used as
usual. As a prerequisite, JITed programs need to be exported through kallsyms
infrastructure.
# echo 1 > /proc/sys/net/core/bpf_jit_enable
# echo 1 > /proc/sys/net/core/bpf_jit_kallsyms
Enabling or disabling bpf_jit_kallsyms does not require a reload of the
related BPF programs. Next, a small workflow example is provided for profiling
BPF programs. A crafted tc BPF program is used for demonstration purposes,
where perf records a failed allocation inside bpf_clone_redirect() helper.
Due to the use of direct write, bpf_try_make_head_writable() failed, which
would then release the cloned skb again and return with an error message.
perf thus records all kfree_skb events.
# tc qdisc add dev em1 clsact
# tc filter add dev em1 ingress bpf da obj prog.o sec main
# tc filter show dev em1 ingress
filter protocol all pref 49152 bpf
filter protocol all pref 49152 bpf handle 0x1 prog.o:[main] direct-action id 1 tag 8227addf251b7543
# cat /proc/kallsyms
[...]
ffffffffc00349e0 t fjes_hw_init_command_registers [fjes]
ffffffffc003e2e0 d __tracepoint_fjes_hw_stop_debug_err [fjes]
ffffffffc0036190 t fjes_hw_epbuf_tx_pkt_send [fjes]
ffffffffc004b000 t bpf_prog_8227addf251b7543
# perf record -a -g -e skb:kfree_skb sleep 60
# perf script --kallsyms=/proc/kallsyms
[...]
ksoftirqd/0 6 [000] 1004.578402: skb:kfree_skb: skbaddr=0xffff9d4161f20a00 protocol=2048 location=0xffffffffc004b52c
7fffb8745961 bpf_clone_redirect (/lib/modules/4.10.0+/build/vmlinux)
7fffc004e52c bpf_prog_8227addf251b7543 (/lib/modules/4.10.0+/build/vmlinux)
7fffc05b6283 cls_bpf_classify (/lib/modules/4.10.0+/build/vmlinux)
7fffb875957a tc_classify (/lib/modules/4.10.0+/build/vmlinux)
7fffb8729840 __netif_receive_skb_core (/lib/modules/4.10.0+/build/vmlinux)
7fffb8729e38 __netif_receive_skb (/lib/modules/4.10.0+/build/vmlinux)
7fffb872ae05 process_backlog (/lib/modules/4.10.0+/build/vmlinux)
7fffb872a43e net_rx_action (/lib/modules/4.10.0+/build/vmlinux)
7fffb886176c __do_softirq (/lib/modules/4.10.0+/build/vmlinux)
7fffb80ac5b9 run_ksoftirqd (/lib/modules/4.10.0+/build/vmlinux)
7fffb80ca7fa smpboot_thread_fn (/lib/modules/4.10.0+/build/vmlinux)
7fffb80c6831 kthread (/lib/modules/4.10.0+/build/vmlinux)
7fffb885e09c ret_from_fork (/lib/modules/4.10.0+/build/vmlinux)
The stack trace recorded by perf will then show the bpf_prog_8227addf251b7543()
symbol as part of the call trace, meaning that the BPF program with the
tag 8227addf251b7543 was related to the kfree_skb event, and
such program was attached to netdevice em1 on the ingress hook as
shown by tc.
Introspection
The Linux kernel provides various tracepoints around BPF and XDP which can be used for additional introspection, for example, to trace interactions of user space programs with the bpf system call.
Tracepoints for BPF:
# perf list | grep bpf:
bpf:bpf_map_create [Tracepoint event]
bpf:bpf_map_delete_elem [Tracepoint event]
bpf:bpf_map_lookup_elem [Tracepoint event]
bpf:bpf_map_next_key [Tracepoint event]
bpf:bpf_map_update_elem [Tracepoint event]
bpf:bpf_obj_get_map [Tracepoint event]
bpf:bpf_obj_get_prog [Tracepoint event]
bpf:bpf_obj_pin_map [Tracepoint event]
bpf:bpf_obj_pin_prog [Tracepoint event]
bpf:bpf_prog_get_type [Tracepoint event]
bpf:bpf_prog_load [Tracepoint event]
bpf:bpf_prog_put_rcu [Tracepoint event]
Example usage with perf (alternatively to sleep example used here,
a specific application like tc could be used here instead, of course):
# perf record -a -e bpf:* sleep 10
# perf script
sock_example 6197 [005] 283.980322: bpf:bpf_map_create: map type=ARRAY ufd=4 key=4 val=8 max=256 flags=0
sock_example 6197 [005] 283.980721: bpf:bpf_prog_load: prog=a5ea8fa30ea6849c type=SOCKET_FILTER ufd=5
sock_example 6197 [005] 283.988423: bpf:bpf_prog_get_type: prog=a5ea8fa30ea6849c type=SOCKET_FILTER
sock_example 6197 [005] 283.988443: bpf:bpf_map_lookup_elem: map type=ARRAY ufd=4 key=[06 00 00 00] val=[00 00 00 00 00 00 00 00]
[...]
sock_example 6197 [005] 288.990868: bpf:bpf_map_lookup_elem: map type=ARRAY ufd=4 key=[01 00 00 00] val=[14 00 00 00 00 00 00 00]
swapper 0 [005] 289.338243: bpf:bpf_prog_put_rcu: prog=a5ea8fa30ea6849c type=SOCKET_FILTER
For the BPF programs, their individual program tag is displayed.
For debugging, XDP also has a tracepoint that is triggered when exceptions are raised:
# perf list | grep xdp:
xdp:xdp_exception [Tracepoint event]
Exceptions are triggered in the following scenarios:
The BPF program returned an invalid / unknown XDP action code.
The BPF program returned with
XDP_ABORTEDindicating a non-graceful exit.The BPF program returned with
XDP_TX, but there was an error on transmit, for example, due to the port not being up, due to the transmit ring being full, due to allocation failures, etc.
Both tracepoint classes can also be inspected with a BPF program itself
attached to one or more tracepoints, collecting further information
in a map or punting such events to a user space collector through the
bpf_perf_event_output() helper, for example.
Tracing pipe
When a BPF program makes a call to bpf_trace_printk(), the output is sent
to the kernel tracing pipe. Users may read from this file to consume events
that are traced to this buffer:
# tail -f /sys/kernel/debug/tracing/trace_pipe
...
Miscellaneous
BPF programs and maps are memory accounted against RLIMIT_MEMLOCK similar
to perf. The currently available size in unit of system pages which may be
locked into memory can be inspected through ulimit -l. The setrlimit system
call man page provides further details.
The default limit is usually insufficient to load more complex programs or
larger BPF maps, so that the BPF system call will return with errno
of EPERM. In such situations a workaround with ulimit -l unlimited or
with a sufficiently large limit could be performed. The RLIMIT_MEMLOCK is
mainly enforcing limits for unprivileged users. Depending on the setup,
setting a higher limit for privileged users is often acceptable.